
Certainly the world of the Web has changed dramatically since 2000, and search engine technology has evolved through a variety of phases. For example, in the pre-Google dawn (Search 1.0), search engines were guided primarily by the words in a page, their location and how they matched the query terms. Google’s great innovation was to demonstrate how search quality could be greatly enhanced by harnessing a new relevance signal: the links between pages. Google’s link analysis technology (PageRank) interpreted links to a page as votes and PageRank was a clever way of counting such votes to effectively compute an authority score for each page, which could then be used during result ranking.As an aside, back in the late 1990’s one of Google’s fellow innovators was a company called Direct Hit, which also argued for the need for new relevance signals. But in the case of Direct Hit the focus was on paying attention to how often users selected a page for a given query, something we will return to later. In the end Google’s PageRank was the right search technology at the right time and the rest, as they say, is history. And so Search 2.0 was primarily driven by relevance signals (links, click-thrus) that originated beyond the content of a page. More recently we have seen further innovation in the direction of vertical search (arguably Search 3.0) for topics such as images, travel, products etc. and the blending of different types of result within a universal search interface (see for example, Google’s Universal Search.
For all of these algorithmic changes the consumer face of web search has not changed dramatically: we still enter (vague) queries and we still wade through long result-lists of links to find what we are looking for (see Figures 1 and 2 below). Under the hood the algorithms have improved and infrastructure has expanded; and search engines have had to respond to the latest SEO ‘tricks’ for boosting content, often at the expense of relevance. But at the end of the day the searcher is embedded in the same search experience that prevailed at the turn of the millennium.
-
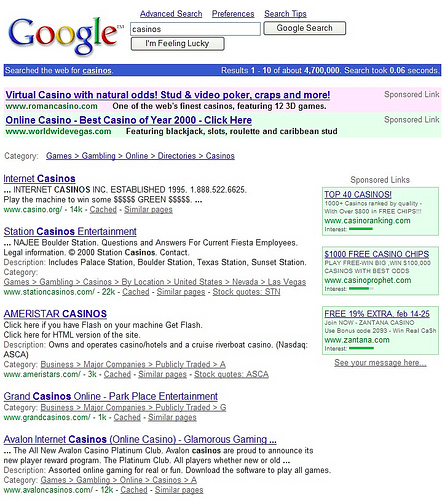
Figure 1. Google’s result-list circa 2001
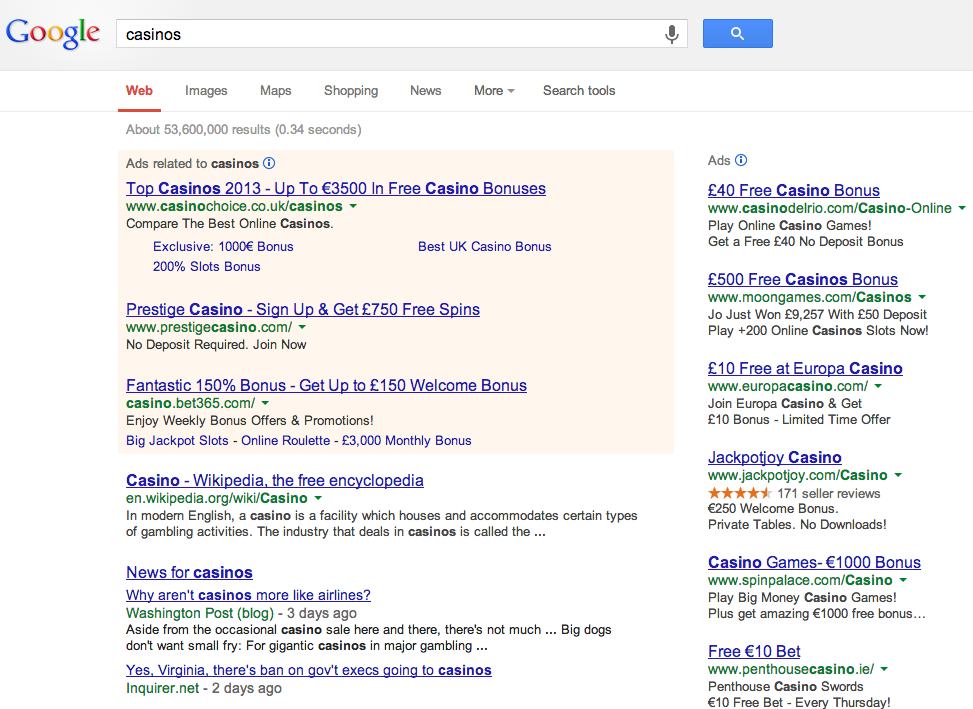
Figure 2. Google’s result-list today, in 2013


The Rise of the Social Web
If search has remained stable the Web has not. The web of links that once dominated has given way to a social Web where content and users share top billing. And there is a growing realisation that the real value is in the data that is generated from user’s interactions with content and each other. This data exhaust hides a wealth of information about identity and behaviour. For example, the interests we wish to project can be mined from our explicit sharing activity (e.g. our tweets, posts, likes etc.), whilst our more basic needs and preferences are encoded in our consumption activities (e.g. pages we read, search queries we submit, and results we click etc.) What we share can be very different from what we consume but both sources of data are providing new sources of innovation around search and discovery.
Taming the Real-Time Web
There are two particularly interesting directions for search and discovery on the Web, as we look to the near future. In the first the emphasis is on the type of real-time data that is generated through social networks in the links we share, the opinions we post, and the content we like. Hilary Mason (until recently Chief Scientist at link shortening service Bit.ly) spoke about how Bit.ly is exploring new types of search services from it’s aggregate click-data, and the URLs it contains, rather than crawling the Web like conventional search engines. By focusing on indexing content that is capturing attention now (based on the URLs people shorten and share using Bit.ly) Bit.ly engineers developed a prototype search engine, rt.ly. Because rt.ly indexes shared content, rather than crawling archived content, it is indexing the Web’s gossip. This provides a complementary service to more conventional search engines, whose objective is to create and maintain a searchable archive of all of the world’s information: today’s gossip, breaking news, and opinions are drowned by the weight of the world’s archival content.
Towards Collaborative Search
Another direction for Web search is the way in which our day to day interactions can help to guide conventional search engines towards a more relevant ranking of results. Didn’t Direct Hit try to harness this type of click-through data back in the late 90’s? Yes and no. Direct Hit’s innovation focused on the overall click-through popularity of a result (more clicks = better ranking) but this left it very susceptible to click-spam. Nevertheless click-through data is clearly a useful signal, but in the right context. The key idea around the idea of collaborative search is that we don’t have to view search as a solitary activity in which searchers submit queries and select results as if their searches existed in complete isolation from the searches of others. The reality is actually very different. Much of the time we are searching for things that others have found: friends and family will often search for the similar holidays or gifts, for example, and colleagues and friends will frequently look for similar information that reflects their needs and interests.
Now, the queries we submit and the results we click provide unique insights into deep interests, especially when we compare these to the search activities of other similar users. Here at HeyStaks this approach allows us to algorithmically match search with similar interests and suggest results based on their similar queries. This allows us to effectively transform a solitary modern web search engine into a search engine that is more social and more collaborative. In short, HeyStaks provides a way for existing search engines or infrastructure to add a layer of collaboration in order to harness the recurring patterns of query and result selections that underlie most search scenarios. The result? Now, when I search on Google for the answer to a technical question to do with my research, or try to find a nice hotel for my next trip, or look for the latest ideas on marathon training, in addition to Google’s algorithmically selected organic results I am also recommended relevant results from people I trust based on their similar query patterns. These HeyStaks results can be many times more relevant than Google’s guesses because they are informed by like-minded searchers, experts on topics that matter to me.
And so, here at HeyStaks we are with Hilary: search is not a solved problem and today’s search engines are not the complete package for our information needs. But they will continue to evolve. And just as paying attention to links allowed Google to rise above the ranks of the purely term-based search engines that came before, by harnessing real-time interactions and social relationships we will all benefit from improved search experiences, helping us to find the right information at the right time, every time.
