
Back in the good ol’ days, before we talked about content curation as a next-generation web service, we lived in a curated web. Yes that’s right. Long before there were social networks, even before there were mainstream search engines, people found content online by navigating catalogs of carefully curated content, collections of hand-picked links, or hierarchies of meticulously organised pages. Back in the day, Yahoo! was the king of the curated web, providing millions of early web adopters with access to a carefully curated hierarchical catalog of pages and links. The catalog still survives today even though, by and large, we web users search for, rather than navigate to, the content we seek, but nonetheless in the pre-dawn of the modern web people located content by navigating through Yahoo!’s comprehensive catalog. Of course, then along came Google. And the rest, as they say, is history.
Reputation Inc. – The Value of Social Reputation on the Recommendation Web
Way back in the pre-Google dawn of the 1990’s Internet there was a much heralded approach to web search by a company called DirectHit. The message was simple: paying attention to the words in a document (and query) was not enough to do a good search job, we need to pay attention to the results people select.
To be fair, the first part of this idea – that the words or terms in a query and document were not enough – was accepted by then; at the time a couple of grad students at Stanford were doing some interesting things with links as a result ranking signal for the same reason. But where Boston-based DirectHit differed was it’s emphasis on engagement signals. For instance. the Direct Hit search engine harnessed the searching activity of millions of anonymous web searchers to rank websites based on often searchers selected a page, how long searchers spent viewing it, and where the page was ranked in the original search results list. Ultimately, Direct Hit’s so-called Popularity Engine ranked search results based on a formula that combined a variety of engagement signals to evaluate the page’s popularity. At the time the idea was fascinating and potentially powerful; so much so that Direct Hit was acquired by Ask Jeeves for more than $500m in stock.
The Selfish Web: Is Sharing Really Caring?
In an earlier post, we described how the term “social search” can be roughly translated to mean “searching the social Web” for many of the offerings out there. We argued that social search can be thought of as a process, not just another source of results. Also, the differing intents behind sharing on social networks and searching may result in lower relevance when using social posts as search result recommendations. Here we will discuss how the social Web – although undoubtedly a useful source of relevant results for searching – may not cover the gamut of peoples’ searching interests and that the motivations behind posts on social media sites may limit their usefulness as a reliable source of search recommendations.
Sharing is only partly caring
The psychology of sharing has been well studied in recent times, with many motivations identified as to why people choose to post things to social media. Altruism, self-promotion, validation, relationship-building; all feature across various studies, as does building thought leadership or authority, image- or brand-construction. Even altruism itself can be viewed as self-serving, though studies have shown that humans may possess an “altruism instinct“.
Public vs Private Parts: Personas & Sharing on the Recommendation Web
The Internet is an archive of our lives. Every event captured, every photo rendered, and every conversation indexed. And, if it can be stored it can be found. Maybe not today but someday, by a friend perhaps, or a future employer, whether we want it to be found or not. This is both liberating and terrifying. But is it creating an incentive for people to hide their true personalities? Are we curating carefully crafted personas online that only disguise our genuine personalities? If so then, what we share may not be what we click and this has some important implications for the future of personalization, sharing, and recommendation on the web.
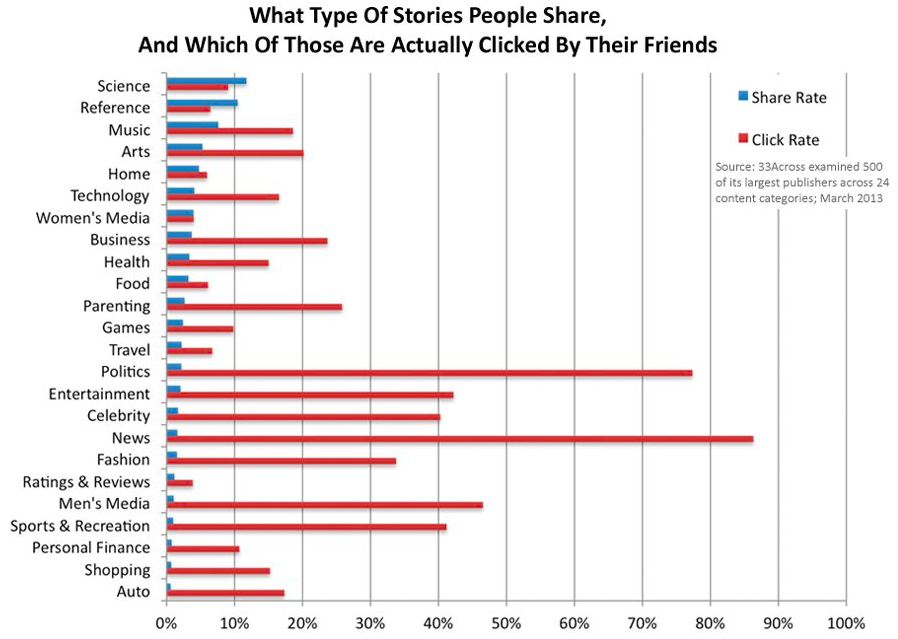
Figure 1. An analysis of what people share versus what is clicked, by 33Across, and based on 450 large publishers and 24 content categories.
Whitepaper – Social Search and Search Analytics in the Discovery Economy: An Enterprise Perspective
-
-

By Prof. Barry Smyth, HeyStaks’ Chief Scientist
-

Knowledge workers continue to struggle when it comes to finding the right information at the right time, leading to high search failure and abandonment rates – 50% of queries lead to failed searches and 44% of knowledge-workers fail to find what they are looking for – a significant cost to enterprise in terms of lost productivity and missed opportunities. One practical solution is for a more collaborative approach to search, which harnesses the past search patterns of experts within an organisation, and works in tandem with conventional search services to provide more relevant and useful results. By harnessing the power of collaborative search, HeyStaks can improve search effectiveness within the enterprise by up to 50% and by fostering improved collaboration HeyStaks will improve engagement, knowledge sharing, and innovation right across an enterprise.
Social search: searching the social Web or a social form of Web search?
For a number of years now, a growing trend in online information retrieval has been “social Web search” (or simply “social search”). It’s a term that continues to be tweaked and defined, and there are some quite different interpretations of what social search actually means. Generally speaking folks interpret social search to mean a form of Web search informed by the searcher’s social graph. The way in which the social graph informs search tends to be searching social feeds from the likes of Facebook, Google Plus and – once upon a time – Twitter. Posts or status updates containing links that match the user’s query can be integrated with regular search results. In this post we explore some of the ramifications of this approach to social search and suggest a different way of looking at things.
The Evolution of Web Search:From Real-Time Discovery to Collaborative Web Search
Certainly the world of the Web has changed dramatically since 2000, and search engine technology has evolved through a variety of phases. For example, in the pre-Google dawn (Search 1.0), search engines were guided primarily by the words in a page, their location and how they matched the query terms. Google’s great innovation was to demonstrate how search quality could be greatly enhanced by harnessing a new relevance signal: the links between pages. Google’s link analysis technology (PageRank) interpreted links to a page as votes and PageRank was a clever way of counting such votes to effectively compute an authority score for each page, which could then be used during result ranking.As an aside, back in the late 1990’s one of Google’s fellow innovators was a company called Direct Hit, which also argued for the need for new relevance signals. But in the case of Direct Hit the focus was on paying attention to how often users selected a page for a given query, something we will return to later. In the end Google’s PageRank was the right search technology at the right time and the rest, as they say, is history. And so Search 2.0 was primarily driven by relevance signals (links, click-thrus) that originated beyond the content of a page. More recently we have seen further innovation in the direction of vertical search (arguably Search 3.0) for topics such as images, travel, products etc. and the blending of different types of result within a universal search interface (see for example, Google’s Universal Search.
New Video: Increasing Website Conversions
Over the past week or so, we’ve been furiously writing, recording, re-recording and editing to bring you our latest video, entitled “Increase Website Conversions with HeyStaks Collaborative Search”. In the video, Maurice (our CEO) leads you through an example of HeyStaks Collaborative Search in action on a travel booking website. The video illustrates how HeyStaks can increase conversions and engagement by making it easier for a user to find the most suitable content for his specific needs. It demonstrates how HeyStaks, recording implicit collaboration between users, can unlock powerful personalization features.
Take a look below.
We’re planning to release a range of similar videos over the coming weeks and months, showing the power of HeyStaks’ products in a range of different situations.